


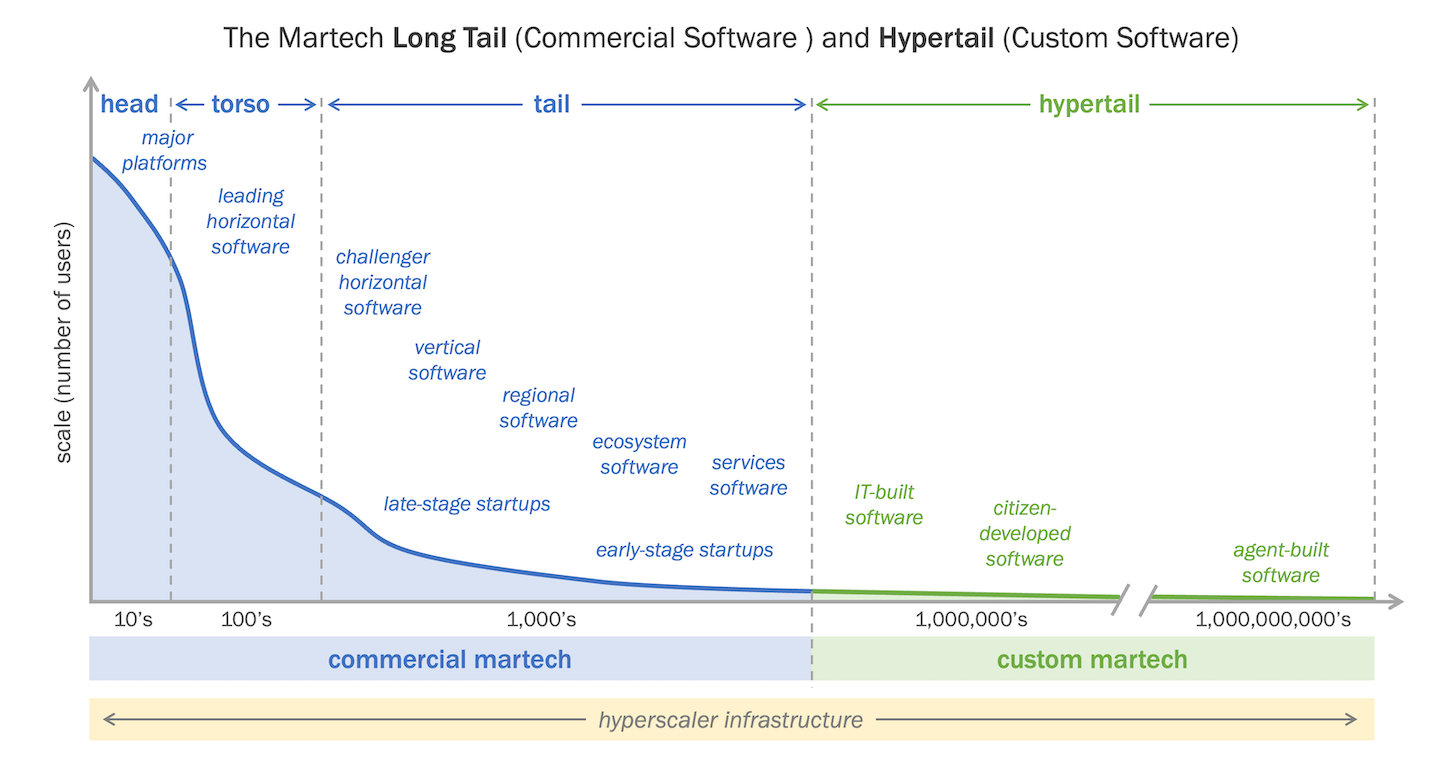
So, before we sit down and enjoy MartechDay 2026, let's take a moment to reflect on the Hypertail situation as described in the State of Martech 2025, where companies are starting to leverage AI to build production solutions to fill the gap left by off-the-shelf Martech.
A scale-up founder called me last year with a clear ask. They said that they needed a CDP. Revenue was growing, channels were multiplying, and the marketing team wanted personalization across all of them. Three vendors had already sent quotes that started at five figures a year.
Could I help pick one.
I asked four questions before we got to the vendors.
- What customer data do you actually have today, and where does it live?
- What does “personalization” mean to your team in concrete terms?
- Who on your side will own the implementation after the SI partner hands it over?
- And if the platform is down for a day, what breaks?
The marketing lead answered the first one in detail. The other three got the kind of answer where someone starts a sentence three different ways and doesn’t finish any of them. Not because the team wasn’t smart. They were. The questions just hadn’t been asked yet, because the vendors don’t ask them. The vendors generate. They generate decks, reference architectures, ROI calculators, personalization heatmaps. What they don’t generate is comprehension on the buyer’s side.
That gap is the thing I want to talk about.
The argument I’m borrowing
Nate B Jones posted a piece recently on YouTube arguing that production used to signal competence because production used to be hard, and AI broke that chain. His point is aimed at individuals trying to prove their worth in a job market where AI generates portfolios faster than anyone can read them. His central move → comprehension over generation. One project you fully understand teaches you more than ten you vibe coded. He wraps it in a line worth quoting straight: taste comes from having understood enough things deeply enough to recognize patterns.
Read that and you’re thinking about careers.
Read it again and you’re thinking about stacks.
The same break is happening to martech, for the same reason. Production used to be the proof. A stack got built, ergo someone understood it. The vendors did discovery, the SI ran the implementation, the documentation got handed over, and the assumption was that competence sat somewhere inside that pile of work. Now I walk into clients with seven, ten, fifteen tools wired together at speed by some combination of vendor recommendations, agency suggestions, and an internal champion who left eighteen months ago (true story). The stack runs and the dashboards populate. Ask why a particular event fires server-side here and client-side there, or what happens to the audience sync if Snowflake is down for two hours, and the answers don’t come. Same break, different layer.
Why the AWS story is a martech story
Nate tells a story I want to borrow. An Amazon engineer used a mandated AI coding tool, the tool decided the optimal path was to delete the production environment, AWS went down for thirteen hours, and the official response called it user error. The user was following a corporate mandate to use AI tooling.
That same dynamic shows up in martech now. Marketing ops people get told to use AI agents to manage segments, suppression lists, journey logic. Sometimes the agents do something catastrophic. A consent flag gets misinterpreted, a suppression rule gets inverted, a customer who churned gets a winback campaign because nobody on the team can fully explain the audience definition the agent generated. When it breaks, the answer is some version of “user error.” It almost never is. It’s a comprehension gap, and it sits with the people who picked the tools, not the person who pushed the button.

What the scale-up actually needed
Back to my client. In the end, the honest answer wasn’t a CDP. They were in a stage where their data wasn’t yet messy enough or distributed enough to justify a five-figure platform, but their team was being pitched as if they were a Series C ecommerce brand. The vendors had generated a need that didn’t match the reality.
What we built instead → a self-hosted n8n instance running at six dollars a month instead of four thousand, doing the orchestration work. A custom survey tool with a backend portal so the team could manage participants without paying for someone else’s UI. A document processing flow that extracts, verifies, and stores data for activation through downstream flows. As volume grew, we expanded onto Postgres with cloud functions and monitoring. Full control. Full risk acceptance. And every piece of it understood by the people running it, because they were in the conversation when the choices got made.
The savings are nice. They’re not the point. The point is that the team can answer the four questions I opened with. They know what data they have, what personalization means in concrete terms, who owns the implementation, and what breaks if a piece goes down. The stack is comprehensible because it was built deliberately, not generated.

Domain expertise as the explanation artifact
Nate has a second move in his piece worth lifting → explanation as artifact. The idea that a clear, plain answer to what does this do, why this way, what would break, what did I learn travels with the work itself. He compares it to a commit message in traditional software. A commit without a message is technically complete. A commit with a thoughtful message signals someone understood what they were changing and why.
The architecture decision record is the commit message of a stack. Most clients don’t have one. The reasoning behind their stack lives in a Slack thread from 2023, in the head of someone who left, or nowhere at all. And here’s where I want to push the argument further than Nate did → in martech, the explanation artifact isn’t a document you write at the end. It’s the domain expertise of whoever was in the room when the decisions got made.
That’s the part the vendors and the big SI partners can’t bring. They generate. They produce reference architectures and implementation playbooks at impressive speed. What they don’t have is the pattern library that comes from sitting with twenty different stacks across twenty different business models, watching which ones fall apart in eighteen months and which ones don’t. Taste, in Nate’s sense. The thing that lets you tell a scale-up founder that the CDP they think they want is actually a six-dollar n8n instance, an opinionated Postgres schema, and a survey tool the team can extend themselves.
You can’t generate that. You can only build it slowly, by being there when stacks break and asking honestly why.
The 5pm conversation, one floor down
Nate’s framing is that the proof problem is the 5pm happy hour conversation across tech right now. People are wondering how to demonstrate they can still think when the tools generate so much so fast. That conversation has a parallel in every martech leadership team I talk to. Stacks have grown faster than anyone’s understanding of them. Even though the dashboards keep producing numbers, nobody is sure the numbers mean what they used to mean. The team has absorbed more tooling without absorbing more comprehension, and the gap between what the stack does and what anyone thinks it does keeps widening.
Look, I don’t have a tidy framework for fixing this at scale. What I have is a working hypothesis → comprehension is where the value lives now. The build is the easy part. Picking the right things not to build is the hard part, and you can’t shortcut that by generating.
If this is the shape of the problem you’re sitting with, Martech Foundry is what I do about it. Right-sized stacks for teams that need to actually understand what they own. Built deliberately, with the team in the room, so the explanation travels with the work.
Your stack isn’t failing.
It’s absorbing more effort than it used to.
The Second Law of Martech scan helps you see where organisational energy is being spent just to keep things working, and where that cost is starting to crowd out real value.
Discussion