


Databricks announced CustomerLake at its Data + AI Summit just now, and the rumor is confirmed: it is a customer data platform. A real one. In 2026 no less. Marketer-facing, built natively inside the lakehouse, with agents doing the work that used to need a data team and a few weeks of lead time. The first agentic CDP a lakehouse has built for itself.
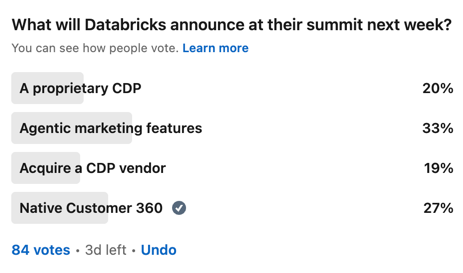
To be fair, I saw it before the keynote. Databricks invited me to a preview and asked what I made of it, which I took as a good sign in both directions, them wanting an independent opinion and me being asked for one. Katy Yuan walked me through the product. For the record, this was preview access under embargo, so weigh that accordingly. I came away more convinced than I expected, and more uneasy about a couple of things than the demo intended.
This is not a write-up of the demo. The screens were nice. What I want to work out is what this does to the category, to the companies that built the category, and to anyone currently holding a CDP decision or a warehouse contract.
Sit tight, because this is my longest article to date.
What it actually is, once you strip the branding
CustomerLake is a marketing application that lives on the lakehouse instead of beside it. That sentence is the whole thing. Every CDP before it, packaged or composable, was in some sense a copy of your data with a marketing interface on top, or a thin layer renting space next to the warehouse and reaching in. CustomerLake is the marketing interface on the data itself. The profiles, the governance, the semantics inherit straight from Unity Catalog rather than being reconstructed by a third party you then have to trust and police separately. Nothing moves. Nothing gets translated across a vendor boundary. The seat that the composable vendors were renting you, the layer between you and your own data, Databricks just built and kept.
A quick word on words, since I am leaning on two of them. Most companies, mid-market especially, still call the place their data lives a warehouse, and the composable pitch spent years training them to. Databricks is a lakehouse, and the difference matters more than it sounds. A warehouse is built for the clean, modeled tables that feed a dashboard or applications. A lakehouse holds those too, alongside the raw events, the behavioral signal, the ML features, the messy unstructured data, all under one governance layer. A CDP that feeds agents needs the second kind of place, because clean tables on their own do not make a decision. So I will say warehouse when I mean the mental model the market still carries, and lakehouse when the architecture is the actual point.
Strip the branding and most of what is on screen is not new. Natural-language querying of customer data already exists. Treasure Data and Amperity have versions of it. Building a campaign by talking to an assistant is not novel either. Zeotap does it, and Hightouch lets you assemble one in conversation with its chatbot. The chat box is not the story, and anyone selling it as the breakthrough is counting on you not having seen the others.
Where Databricks goes a step further is context. You can hand it the documents a marketer actually plans from, a brief, an H2 plan, the positioning doc the PMM passed down, and point it at the systems where those live. That is more useful than feeding a model column metadata, and it is the most marketer-native version of context I have seen so far, the same idea I worked through in the Contextual CDP series. Any of the others could build the same upload box in a quarter or less. The same is true of decision simulation, where the system plays a campaign forward across synthetic profiles before it sends and shows why a given person would receive a given message. It is a good use of Databricks' modeling muscle, and still nothing a competitor could not copy.
The one part none of them can answer by shipping a feature is what sits underneath. CustomerLake runs on the data with no third party in the middle. Everything on the screen is buildable. That is not.
There is an obvious objection here, and Databricks has an answer for it. Most large companies do not keep everything in one place, so a CDP that only saw Databricks-resident data would be half-blind. Through Lakehouse Federation, CustomerLake can query trusted data where it actually lives, in Snowflake, BigQuery, cloud object storage, operational databases, without first copying it into Databricks. That is a real answer, and a better one than the composable vendors gave you, because the governance travels with the query instead of being rebuilt on the far side. Hold that thought. It complicates the neat ending everyone wants to write.
One thing gave me real pause, and I am holding it loosely, because twenty minutes is not an audit. The demo leads with Genie doing the assembly and barely touched the manual path. Katy was clear afterward that everything the agent does has a full GUI underneath it, you can still build an audience by hand the traditional way, it just does not demo as well. Fair enough. The part that gave me said pause was the default. Human-in-the-loop is everywhere, a sign-off at each step, but the path of least resistance is to let the agent propose and then approve its work, and defaults shape behavior more than capabilities do. It is a statement about who is expected to run the work. I wrote a piece a while back, Letting go of control, about how the move to agentic systems is a leadership question well before it is a technical one, the same discomfort a founder feels the first time they hand real decisions to a team. The job goes from micromanager to designer, you set the parameters and let the system work inside them, which only pays off if you trust it. CustomerLake is built on that bet, that marketers will let go sooner than they think. Whether they should is a separate article.
Katy's proof point was the concrete kind. One large hardware maker had been running two separate workspaces just to keep its B2B and B2C data apart. On CustomerLake that becomes one model on one platform, because the governance boundary is the lakehouse, not the tool. That is the embedded pitch in a real shape rather than a slogan.
The rest is consumption-priced with no platform fee, and the sends handed off to partners through the standard set of connectors you have come to expect from a marketing platform, the tens, if not hundreds, available for easy integration. Hold onto that pricing choice. It is the part that reorders the market.
One correction, because someone will raise it. The agentic-CDP label predates this launch. GrowthLoop has called itself an agentic, composable CDP for the better part of a year, and it runs natively on Databricks, Snowflake and BigQuery alike. Databricks did not coin the category. What it brings is the ground it stands on. GrowthLoop is agentic and composable built on the data cloud, a tenant on top of it. Databricks is the data cloud. Same words, and one of them owns the building.
Where I was right, and the move I missed
I should own where I landed on this, because I landed wrong in public. I argued, more than once, that Databricks would not ship a CDP. The reasoning held up until the keynote and I still think it was good reasoning. Databricks had never built or bought a destination application. It buys infrastructure and folds it in. Its pricing rewards compute over seats. It had just deepened its Adobe partnership and put money into Hightouch's last round. Every signal pointed at a company that wanted to be the data underneath everyone's marketing tools, not the tool.
The part I got right I said to Katy on the call. I brought up an old piece I wrote on data gravity, one I had reread before the demo, where I had landed on a plain conclusion. When the data already lives in one place, you build the thin layer next to it instead of routing through someone else. That is exactly what they did. Build over buy, because the expensive thing, the data, is already home. Governance inherited instead of rebuilt. The mechanism was never in question.
There is a detail in who built it that makes the point sharper. Engineering for CustomerLake is run by Tasso Argyros, who founded and ran ActionIQ. Justin DeBrabant, another ActionIQ alumnus, leads product. Michael Trapani, also out of ActionIQ, runs the go-to-market, and Katy herself spent three years at Census. The people who spent the back half of the last decade building the composable and packaged CDPs are now inside the lakehouse, building the thing that absorbs both. Databricks did not need to buy ActionIQ. It hired the people who knew where the bodies were buried and pointed them at data it already holds.
What I missed was nerve. I assumed they would build the data and decisioning layer and leave the marketer-facing surface to partners, the screens, the campaign workflow, the audience builder. They built the surface too. A company that had only ever sold infrastructure just moved up the stack and opened a storefront aimed at a buyer it had never sold to. A lakehouse deciding it wants to be the application.

Was anyone actually blindsided
It is tempting to frame this as a surprise attack on the composable vendors. It was not. They paved the runway it landed on. Hightouch published a piece called "make Databricks your CDP." GrowthLoop runs natively on Databricks. Simon Data and the rest pushed the same thesis, pull everything into the warehouse and activate from there. They won that argument so completely that the warehouse ended up with a fully paved on-ramp to build its own front door, which is roughly where I left things in The CDP you weren't supposed to buy. The writing was on the wall, and the composable players are the ones who wrote it. The irony does not escape me.
Which raises the more interesting version of the question. If this was visible, did they price it in. Some clearly did. GrowthLoop leaned into agentic and causal decisioning, the parts that are harder for a warehouse to copy from a standing start. Others spent the runway selling proximity to data they did not own, which is a fine business right up until the owner decides to occupy the space. Inevitability is not the same as readiness. The gravity was always pointing here. The question each of them has to answer now is whether they saw it early enough to have a second act loaded.

Who feels it, and the math underneath
A warehouse-native CDP does not land evenly. It lands hardest on the middle, the composable and reverse-ETL vendors whose whole pitch was that they sit beside your warehouse and activate from it. For a customer already running everything on Databricks, that pitch lost its reason to exist. The lakehouse does the same job with no data leaving the building and governance it already trusts.
Jake Van Clief made an argument about AI agents that lands cleanly on this. Agents, he says, are infrastructure, not a company, and trying to build the infrastructure is a way to lose to the people who build infrastructure for a living. His examples? When the internet was already built, Google added a layer on top and Amazon skipped the infrastructure entirely to become a different kind of company, before later becoming the builder with AWS. The names that won, Netflix, Spotify, Uber, Airbnb, were the ones using the infrastructure rather than racing it. "You think you can compete with the builders?" he asks. "Go ahead. Go for it." Far more value got created on top of the infrastructure than beside it.
Now read that with the warehouse as the infrastructure and the composable CDP as the layer trying to be a company. A vendor selling a better activation engine or a smarter agent on top of Databricks is building infrastructure next to the company that owns the infrastructure, and that company just shipped its own. The ones that last will do what Netflix did, use the warehouse to deliver something it has no interest in building itself, rather than competing with it on the same ground. Not with Databricks alone. The day the next warehouse builds the same front door, that line, between the layer racing the builder and the company that just uses it, is the only one that matters.
The channel layer is fine, and that is the clever part of the design. Databricks made the engagement platforms partners instead of targets. It built the data, the decisioning and the workflow, then handed the send to them. Twilio tried the opposite years ago, bought Segment and then competed with the engagement vendors on top of it, and the combination never found its feet. Databricks took the lesson. Feed the channel, do not fight it.
Then there is the pricing, which reorders the whole market. Databricks can give the CDP away. The pricing carries no platform fee because the value is captured downstream, in the compute the platform bills every time it builds a profile or resolves an identity. The independent CDP has to charge for the CDP itself, because that is its only line of revenue.
You cannot win a price war against a company that does not need your product to make money.
That asymmetry is the whole story, and it is what a feature-by-feature comparison will miss.
Consumption pricing has a graveyard, and I said as much on the call. mParticle pushed a pay-as-you-go model and it never really took, and the question got quieter once the company was acquired. The difference is that an independent charging by consumption is betting against its own predictability. Databricks already bills this way for everything else. For them it is not a gamble, it is the house model, and the CDP is one more meter on a machine that was already running.
Every action has a reaction
Databricks put money into Hightouch's last funding round, on the thesis that customers were building composable CDPs on the lakehouse. It deepened its Adobe partnership again this spring, wiring Delta Sharing and a Genie connection into Adobe's marketing agent so Experience Platform could query Databricks data without copying it. Adobe is a customer here as much as a partner, Experience Platform itself runs on Databricks, so that relationship is closer to an alliance than a contest. The composable middle is where the overlap bites, hard. I asked Katy about the fallout. Her answer was that co-opetition is the name of the game, that CustomerLake stays open and composable, that the plan is to fit a customer's stack rather than tell them to rip and replace. I believe she means it. I also think the economics do not care what anyone means as I will elude to in a bit.
Notice what the move was not. Databricks did not acquire anyone. It did not buy Hightouch or a packaged CDP and bolt it on. It built the thing itself, because it already held the one part that is genuinely hard to come by, the data. The interface, the agents, the connectors are comparatively cheap once you are sitting on the warehouse. That is more aggressive than an acquisition and, oddly, more courteous. I have heard from people I trust that Databricks gave several partners a heads-up before the announcement rather than letting them find out from the keynote. That is more grace than this industry usually extends, and it tells you Databricks knows exactly whose business it is walking into.
There is a twist worth mentioning, because it complicates my tidy action-and-reaction setup. Hightouch did not wait for the keynote. The day before Databricks announced CustomerLake, Tejas Manohar put out Hightouch's own agentic-CDP manifesto, getting ahead of it to claim the category on composable terms (eventhough Simon and GrowthLoop already did). The timing reads as pre-emptive, and from a close Databricks partner who almost certainly knew what was coming, deliberate. He does not pick a fight, Hightouch still taps Genie under the hood. He redraws the line.
"Data warehouses may even claim the title of customer data platform. Fair enough,"
he writes, before planting the flag:
"Hightouch will remain the place where marketing gets done."
The product under it is a real pivot, a harness of long-running agents that research, verify, prioritize and draft opportunities in the background, and on agentic ambition it reads as further along than what Databricks showed me. But it is a lead, not a moat. A harness is software on top of infrastructure, the thing that gets copied, and Databricks has the models, Genie and now CustomerLake to build the same loop on data it already owns.
Which is why a feature race is the wrong frame.
Parity does not decide a fight when the pricing models differ. If Databricks matches Hightouch feature for feature it can still give the result away, because it bills the compute either way while Hightouch has to charge for the product itself. The durable move is the one Hightouch is reaching for in its positioning rather than its harness: be the neutral intelligence and agentic marketing layer that floats across Snowflake, Databricks and BigQuery, owning the cross-cloud, where-marketing-gets-done ground the lakehouse has no reason to chase.
That is the "Netflix" turn, if they take it. If the story becomes "we have the better agents", they are back in the parity trap. The lane that survives is the other one, your intelligence should not be trapped in anyone's warehouse.
I would not call it yet.
Newton's third law is the right lens here, because a move this size produces an equal and opposite one. Probably not, in the near term, on the partners who built their whole motion around recommending Databricks next to their own product. They are too entangled to retaliate, and the early word should keep the peace, for now.
The reaction worth watching is one level up, from the other platforms sitting on the same gravity. Snowflake is the obvious one. Google has BigQuery and an ads business that already thinks in audiences. AWS holds the data in Redshift and the identity primitives in Entity Resolution, but it has always preferred to arm the partners rather than become one, which is its own kind of answer. Microsoft barely has to follow at all, because Dynamics 365 Customer Insights is already a type of CDP, and it is already being pulled natively into Fabric.
Even the European players like OVHcloud have a data-sovereignty argument Databricks cannot easily match. The day one of them decides it cannot let the marketer-facing surface belong to a rival, the action Databricks took this week becomes the reaction everyone else is forced into.
Have we circled back to the monolith
The uncomfortable possibility is that this looks like a return to the thing composable was built to escape. One vendor, one platform, the whole stack under one roof. The packaged-CDP era was a monolith. Salesforce is still the gravitational version of one, the black hole that pulls a marketing organization in and bills it for the privilege of never quite leaving. So is the lakehouse slash warehouse just the next monolith with better architecture.
I do not think it is the same situation. You still own the data, in your tenant, under your governance. It is still composable in the sense that counted, the activation can point outward and the data does not have to move into someone else's system to be useful. What Databricks took back is not your data, it is the layer between you and your data. A monolith you own the foundation of is a different proposition from one you rent end to end, and this is the more democratized version, marketers acting without a four-week queue through the data team. Ownership tends to scatter until no single team owns the middle, the problem I picked at in Who's actually in charge?. Collapsing the data and engagement zones onto one platform answers that, or at least papers over it. Whether that distinction holds up against a consumption bill and a roadmap you do not control is the open question, and it is the same one every platform consolidation eventually forces. We may not be back at the monolith, but we are closer to its gravity than the composable pitch wanted us to get.
The starting gun
The launch matters less as a product than as a signal. Databricks moved first, and first forces the rest of the field to decide whether it follows. The warehouses behind it hold every piece they would need, the storage, the identity resolution, the model infrastructure, the same pull dragging customer data inward. Once one of them proves a marketer will build a campaign inside the data platform, the surface stops being optional for any of the others.
Notice how fast this arrived. Email held marketers for most of a decade. Packaged CDPs ran the 2010s. Composable got maybe five years before agentic showed up behind it, and the gap from composable to agentic is shorter than the gap from packaged to composable. The eras are compressing. If that is real, then "final resting place" is the kind of thing every era says about itself right before the next one arrives. Agentic may be the genuine new floor of the category, or it may be one more layer that the next technology makes quaint faster than the last one did. My honest bet is that the substrate keeps winning and the surface keeps getting rebuilt, which makes the endgame less a destination than a direction of travel. The CDP keeps moving toward the data. CustomerLake is the furthest it has gotten, not necessarily the last stop.
What a Databricks customer should actually do
The practical question divides cleanly, and it is worth being precise because the wrong move here is expensive in both directions.
If you already run a composable CDP on the lakehouse, you are not in danger, you are in leverage. You have a working stack and a credible second option from your own data vendor, which is close to the best position you can hold going into a renewal. The move is not to tear anything out for a private preview. It is to pilot, to scope honestly what CustomerLake covers against what you are paying your incumbent for, and to let the existence of a free-at-preview alternative do some quiet work on your next contract. Most of the value here is negotiating value, today.
If you are still choosing, the shortlist you drew up a few months ago is missing a column. That does not mean pick Databricks. It means the build-versus-buy math changed under the decision, and an evaluation that ignores the warehouse-native option is now incomplete. The risk is picking a standalone CDP on a multi-year contract just as the platform underneath it starts offering the same function for the cost of the compute.
If you are on Snowflake or BigQuery, this is a weather report rather than a storm. The same gravity that produced CustomerLake is acting on your platform too, and the incentives say your data vendor eventually offers a version of this. Plan as if it will.
That re-scoping, where a CDP decision runs into identity, governance and the rest of the stack around it, is most of what I spend my time on. I built Martech Stack Builder for the part where you have to see the whole stack before you can judge what any one piece should be. The ground moved this week. If you have a decision open, it is worth a fresh look before you sign.
What the warehouse still cannot buy
So, is this the end of the CDP? For Databricks customers, the standalone CDP just got much harder to justify, and that is a real change in a category that spent a decade insisting it was essential. For everyone else, the independents have a clear job and a visible clock.
The thing a warehouse cannot buy is the thing that was always hardest. Owning the data and the workflow sits a long way from winning the marketer, and channel trust is one asset a data platform does not get for free. Neutrality across clouds used to be the other, and this is where I have to update my own argument. I assumed CustomerLake would only see Databricks-resident data, which would have handed the multi-cloud enterprise straight back to the independents. Lakehouse Federation closes most of that gap, since Databricks can reach into Snowflake and BigQuery and the rest, so the simple version of the neutrality pitch is weaker than I first had it. What federation does not close is the difference between reach and neutrality. Pulling a competitor's data through Lakehouse Federation still runs it across Databricks' control plane, its governance, its bill, and its roadmap. A genuinely neutral vendor has no preferred platform to draw you toward, and that is the one thing a lakehouse reaching across clouds can never quite be. Databricks built a strong answer to a question marketers have not really been asking, whether their data platform should also run their campaigns. Whether they want that is what the next year decides.
I have changed my mind on this once already, in public, so take this with the appropriate salt. My honest position is that two things are true at once. The structural move is real and the economics are brutal for the middle. And adoption will be more cautious and exploratory than the keynote suggests. That gap, between what is now possible and what marketers will actually do, is usually where the interesting part of a category lives.
Two questions I cannot settle from here. Does the warehouse take the marketer, or only the seat the composable layer was keeping warm? And is this a circle back to the monolith, or a genuinely different shape? I have a guess on each. I would rather hear yours, especially when it lands opposite mine.
Do you have any questions after reading this article?
Or need support with Databricks, or your Martech projects?
Discussion